Caching Strategies …
Recently I got a opportunity to study about cache implementations in a web app so that we could adopt one in our production environment. I was amazed by the strategies and ideas used in this vast area of software architecture. So I think I can share the knowledge I have gained through a series of articles starting with this one.
What is a Cache ?
Cache is a component that stores portions of datasets( i.e part of the actual data that has been provided to the consumer) which took large amount of time to calculate or to retrieve from the back-end system. Using cache we can reduce additional round-trips for frequently used data i.e cache usually stores the most frequently data, and on request the data can be served without reaching any back-end services.
Hit or Miss :
A cache hit happens when the data is already available in the cache and can be returned without any other operation. If the data is not present within the cache, the cache responds with a cache miss, and if permitted obtain the value from the underlying back-end system and cache it before returning it to the requestor.
Why we need Caching ?
Consider we don’t have a caching layer and all the content is retrieved directly from the database itself. As a result our database will become a single point of failure. Also there will be a bottleneck at peak times resulting in users suffering with long loading times and as well as with high latencies (latency - amount of time it takes the host server to receive and process a request).
To avoid this scenario think of a cache in between the database and the web server requesting resource on the database. The cached content( long processing queries, frequently accessed but not frequently changed data etc.) can be obtained fast.
A good caching strategy can offer lots of advantages and reduces the amount of money spent on hardware to achieve similar goals.
Benefits:
Improved Responsiveness : Cache provides the content faster and prevent additional network calls to back-end resources.
Decreased Network Costs : Depending on the caching strategy content is available in multiple regions inside the network path/ or world. This way the content moves geographically closer to the user and network activity is reduced.
Improved Performance With Same Hardware: As we saw cache stores content that is already obtained from a back-end resource, as long as it is valid. This frees up the server from those complex queries running up again and again and allows it to run more requests on the same hardware.
Caches can also serve as a backup when there is an emergency due to any failure in back-end services. The server goes into a RO(Read Only) mode and render contents based on the cache.
How To Cache:
We have seen the benefits of caching and disadvantages of not having a cache layer. Now we can see how to implement a caching layer within our applications.
Cooperative Caching/ Distributed Caching:
The Cooperative Caching, also known as Distributed Caching, multiple distinct systems(normally referred to as cluster-nodes) work together to build a huge shared cache.
It is a extension of traditional concept of cache ( in memory caches). A distributed cache may span multiple servers so that it can grow in size and in transactional capacity.
Implementation of Cooperative Caches is simple, it route requests to all nodes. They look for someone to respond or provide more intelligent partitioning system, normally based on consistent hashing to route the request to a node containing the requested key.
The general strategy is to keep a hash table that maps each resource to the corresponding machine. Therefore, when requesting resource A, from this hash table we know that machine M is responsible for cache A and direct the request to M. At machine M, it works similar to local cache (in memory cache). Machine M may need to fetch and update the cache for A if it doesn’t exist in memory. After that, it returns the cache back to the original server.

The above image shows the Cooperative cache layer with several set of nodes that are linked together. The HazleCast JCache client is the java client for hazlecast cache framework ( Hazlecast is an in memory data grid for distributed caching)
The examples frameworks for Distributed Caching are HazleCast, Couchbase, Memcached, Redis, Riak etc. ( wikipedia_link )
Partial Caching:
Partial Caching describes a type of caching where not all data is stored inside the cache. Depending on certain criteria, responses might not be cacheable or are not expected to be cached(like temporary failures).
A typical example for data where not everything is cacheable is websites. Some pages are “static” and only change if some manual or regular action happens. Those pages can easily be cached and invalidated whenever this particular action happened. Apart from that, other pages consist of mostly dynamic content or frequently updated content(like stock market updates) and shouldn’t be cached at all.

The cache rule engine checks for the criteria defined(based on business rules) and if the resource is cacheable it will be stored in cache engine and retrieved from the Caching Layer henceforth. If not the resource will be served from the back-end service every time.
Geographical Caching:
Geographical Caches are located in strategically chosen locations to optimize latency on requests, hence mostly used for providing website content( static resources such as javascript and css files). It is also known as Content Delivery Network(CDN)
There will be a central cache and when the resource is requested at first the local cache will store a copy of the resource and serve the assets from the local cache as long as it is valid. This mechanism works well for static resources which will change less often.
The general practice is that to keep regional caches smaller than the central cache due to the fact that regional caches tend to serve data based on language or cultural differences
The geographically nearest cache is most often determined by geo-routing based on IP addresses(https://ns1.com/resources/how-geographic-routing-works) based on DNS routing or using a proxy server which redirect to certain IP addresses using HTTP Status 302(Found)
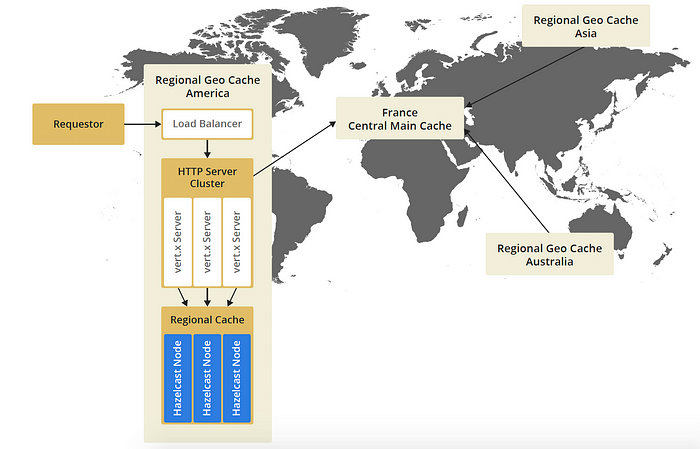
The requestor request a resource in America, based on the ip the request is routed to a local cache in America. The resource is not found in cache which then request the resource from the central cache in France. The resource will be stored as a copy in local cache and then served to requestor. Whenever the requestor requests again the same the resource it will only be served from local cache.
Preemptive Cache:
A Preemptive Cache itself is not a caching type like the others above but it is mostly used in conjunction with Geographical Strike.
Preemptive — taken as a measure against something possible, anticipated, or feared; preventive; deterrent;
As the name suggests preemptive cache predicts that the resources might be requested and gets the cache populated on startup with the help of a warmup engine.
The idea is to load the data from any back-end service or central cache cluster even before the data is required by the requestor.
benefits
- Access time of the cached elements will be constant.
- Prevents access of single elements from becoming unexpectedly long.
issues:
- Building a preemptive cache seems easy but it does requires a lot of knowledge of the cached domain and the updated workflows.

The warmup engine is initialized on server startup and populates the hazleCast cache with the possibly requested data from back-end service
Latency SLA Caching:
Some companies do a Latency( The time required to serve a user request ) SLA( Service Level Agreement) on their APIs to their consumers. They agree that their APIs will give a response within the certain time.
At times when we are using caches, we might face a slow cache or an overloaded cache. At that time we can’t achieve the latency SLA on our API request provided to our consumers. To solve this a latency SLA Caching mechanism is proposed.
There are two options to implement Latency SLA Caching:
Timeout:
The first option is timeout to exceed before the system either requests the potential element from the original source( in parallel to already running cache request) and uses whatever returns first.

This option can and will serve our latency SLA promise and will be efficient on serving the resource. The problem is that on a difficult scenario the server is queued up with lot of requests.
Parallel Queries:
The other option is to fire both requests in parallel( to cache and data source) and take whatever returns first. But this approach is entirely against the idea of caching and every resource is requested at both data source and cache which is seriously not recommended.

But if there are more than one caching layers we can fire the request at the first and second nearest cache in parallel.
The above strategies are some of the widely adopted caching strategies. We will continue our discussions towards caching strategies, eviction procedures etc. in our upcoming articles
ref: www.hazlecast.com